

Δημοσίευση δεδομένων με προστασία ιδιωτικότητας
(t-anonymization, L divercity και άλλα χρειαζούμενα...)
Βιβλιογραφική αναφορά σε αυτή τη σελίδα:
2020
Δημοσίευση δεδομένων με προστασία ιδιωτικότητας
(t-anonymization, L divercity και άλλα χρειαζούμενα...)
Βιβλιογραφική αναφορά σε αυτή τη σελίδα:
2020
Εισαγωγή
Το πλήθος των ψηφιακών πληροφοριών που έχουν συσσωρεύσει σήμερα οι κυβερνήσεις, οι επιχειρήσεις και τα διάφορα άτομα προσφέρουν τεράστιες ευκαιρίες να πάρουμε διάφορες αποφάσεις με βάση τη γνώση που μας παρέχουν αυτές οι πληροφορίες. Εντούτοις τα εξατομικευμένα δεδομένα που υπάρχουν στους πίνακες όταν υφίστανται στην αρχική τους μορφή, συχνά περιέχουν ευαίσθητες πληροφορίες και η δημοσίευση τους παραβιάζει άμεσα το ατομικό απόρρητο.
Αυτό που γίνεται λοιπόν είναι να δημιουργούνται πολιτικές και να δίνονται κατευθυντήριες γραμμές που περιορίζουν τα δεδομένα προς δημοσιοποίηση αλλά και να φτιάχνονται κανόνες που αφορούν τη χρήση και την αποθήκευσή τους.
Εντούτοις, αυτή η προσέγγιση έχει το μειονέκτημα ότι είτε αλλοιώνει υπερβολικά τα δεδομένα, είτε απαιτεί ένα πολύ υψηλό επίπεδο εμπιστοσύνης το οποίο όπως είναι φυσικό δεν μπορεί να επιτευχθεί όταν εμπλέκονται τόσοι πολλοί άνθρωποι και οργανισμοί στα διάφορα σενάρια ανταλλαγής δεδομένων.
Καθίσταται λοιπόν σχεδόν υποχρεωτικό, να αναπτυχθούν μέθοδοι και εργαλεία που να αφορούν τη δημοσίευση δεδομένων σε ένα εχθρικό περιβάλλον, έτσι ώστε και να παραμένουν πρακτικά χρήσιμα αλλά ταυτόχρονα να διατηρείται η προστασία της ιδιωτικής ζωής του κάθε ατόμου. Αυτός ο στόχος ονομάζεται Δημοσίευση Δεδομένων με Προστασία Ιδιωτικότητας (ΔΔΠΙ) (privacy-preserving data publishing -PPDP).
Ουσιαστικά ο εκδότης των δεδομένων έχει έναν πίνακα της μορφής D (Πλήρες αναγνωριστικό, Οιονεί-αναγνωριστικό, Ευαίσθητα Δεδομένα, Μη ευαίσθητα δεδομένα) όπου.
Πλήρες αναγνωριστικό (explicit identifier) είναι ένα σύνολο χαρακτηριστικών, όπως το όνομα, ο αριθμός ταυτότητας, το ΑΦΜ κλπ. που περιέχουν πληροφορίες που προσδιορίζουν ρητά τα άτομα σε κάθε γραμμή του πίνακα.
Οιονεί-αναγνωριστικό (Quasi-Identifier-QID) είναι ένα σύνολο χαρακτηριστικών που θα μπορούσαν ενδεχομένως να οδηγήσουν στην αναγνώριση των ατόμων σε κάθε γραμμή (εγγραφή) του πίνακα.
Τα Ευαίσθητα Δεδομένα (Sensitive Attributes) συνίστανται σε ευαίσθητες πληροφορίες για συγκεκριμένους ανθρώπους, όπως μια ασθένεια, η μισθολογική κατάσταση και η κατάσταση αναπηρίας, ενώ τα Μη Ευαίσθητα Δεδομένα (Non Sensitive Attributes) περιέχουν όλα τα χαρακτηριστικά που δεν εμπίπτουν στις προηγούμενες τρεις κατηγορίες.
Τι είναι η ανωνυμοποίηση
Ο όρος ανωνυμοποίηση αναφέρεται στην προσέγγιση για Δημοσίευση Δεδομένων με Προστασία Ιδιωτικότητας η οποία προσπαθεί να κρύψει την ταυτότητα ή/και τη ευαίσθητα δεδομένα των ατόμων σε κάθε εγγραφή, διασφαλίζοντας ότι τα ευαίσθητα δεδομένα θα διατηρούνται ώστε να αναλύονται επιστημονικά. Αυτό που πρέπει να γίνει λοιπόν είναι να καταργηθούν από το αρχείο όλα τα πλήρη αναγνωριστικά.
Όμως, ακόμα και με την κατάργηση όλων αυτών των ρητών αναγνωριστικών, υπάρχει και πάλι ενδεχόμενο να αναγνωριστούν τα άτομα σε έναν πίνακα όπως ακριβώς συνέβη με τον Γουίλιαμ Γουέλντ, πρώην κυβερνήτη της Μασαχουσέτης.
Όταν η Επιτροπή Ομαδικών Ασφαλίσεων της Μασαχουσέτης κοινοποίησε τα δεδομένα των νοσοκομείων της περιοχής για οικονομική και ερευνητική αξιοποίηση, δημιουργήθηκαν διάφορες ανησυχίες σχετικά με το ποια χρήση θα μπορούσαν να κάνουν οι ασφαλιστικές εταιρίες, γνωρίζοντας την ταυτότητα των ανθρώπων που νοσηλεύτηκαν στα νοσοκομεία. Ο Γουίλιαμ Γουέλντ, κυβερνήτης τότε της Μασαχουσέτης, διαβεβαίωσε το κοινό ότι η Επιτροπή είχε προστατεύσει την ιδιωτική ζωή των ασθενών διαγράφοντας τα σαφή αναγνωριστικά στοιχεία, όπως είναι το όνομα, οι αριθμοί ασφάλισης κλπ..
Σε απάντηση, η μεταπτυχιακή φοτήτρια Σουίνι, που ασχολούνταν με την ασφάλεια των δεδομένων, άρχισε να ψάχνει το αρχείο του νοσοκομείου της περιοχής για δεδομένα που αφορούσαν τον ίδιο τον κυβερνήτη.
Ήξερε ότι ο κυβερνήτης κατοικούσε στο Κέιμπριτζ της Μασαχουσέτης, μια πόλη 54.000 κατοίκων και επτά ταχυδρομικούς κωδικούς. Έναντι είκοσι δολαρίων, αγόρασε τους εκλογικούς καταλόγους της πόλης οι οποίοι περιελάμβαναν μεταξύ άλλων, το όνομα, τη διεύθυνση, τον ταχυδρομικό κωδικό, την ημερομηνία γέννησης και το φύλο κάθε ψηφοφόρου.
Συνδυάζοντας αυτά τα δεδομένα με τα αρχεία του νοσοκομείου, η Σουίνι βρήκε εύκολα τον κυβερνήτη. Μόνο έξι άνθρωποι είχαν νοσηλευτεί με την ίδια ημερομηνία γέννησής, μόνο τρεις από αυτούς ήταν άνδρες, και από αυτούς, μόνο ένας είχε τον Τ.Κ. του κυβερνήτη. Με μια θεαματική κίνηση η δρ Σουίνι έστειλε στο γραφείο του όλο το ιστορικό νοσηλείας μαζί με τις διαγνώσεις και τις συνταγές!
Είναι φανερό ότι καθένα από αυτά τα χαρακτηριστικά δεν θα ήταν από μόνο του ικανό να ταυτοποιήσει το άτομο σε μια εγγραφή, εντούτοις ο συνδυασμός τους, αυτό που ονομάσαμε «οιονεί αναγνωριστικό», μπορεί πολύ συχνά να οδηγήσει σε ταυτοποίηση. Είναι χαρακτηριστικό πως έχει αποδειχθεί ότι το 87% του πληθυσμού των ΗΠΑ μπορεί να ταυτοποιηθεί πλήρως με βάση μόνο τέτοια οιονεί αναγνωριστικά όπως ακριβώς συνέβη και στην περίπτωση του κυβερνήτη.
Για την εκτέλεση αυτών των επιθέσεων διασύνδεσης αναγνωριστικών, ο εισβολέας χρειάζεται να γνωρίζει δύο πράγματα εκ των προτέρων:
α. τη θέση του ονόματος του θύματος στα δημοσιευμένα στοιχεία.
β. το οιονεί αναγνωριστικό του θύματος.
Αυτή η γνώση μπορεί να προσεγγιστεί με απλή παρατήρηση των δεδομένων.
Για παράδειγμα, στην περίπτωση του Γουέλντ η επιτιθέμενη ήξερε ότι ο κυβερνήτης είχε νοσηλευτεί στο νοσοκομείο, διότι το είχε δείξει η τηλεόραση και είχε γίνει μεγάλος ντόρος στα ΜΜΕ, αφού εκείνος είχε καταρρεύσει μπροστά στις κάμερες. Κατά συνέπεια γνώριζε ότι το ιατρικό αρχείο του θα εμφανιζόταν στην βάση δεδομένων των ασθενών που είχε δοθεί στη δημοσιότητα. Επίσης, δεν ήταν δύσκολο να αποκτήσει τον ταχυδρομικό κωδικό, την ημερομηνία γέννησής του και το φύλο του, τα οποία της χρησίμευσαν ώστε να σχηματιστεί το «οιονεί αναγνωριστικό» που χρειαζόταν.
Για να αποτραπούν επιθέσεις αυτού του είδους, οι ονομαζόμενες επιθέσεις διασύνδεσης δεδομένων, ο εκδότης δεδομένων πρέπει να παρέχει έναν ανώνυμο πίνακα της μορφής: Τ (Οιονεί αναγνωριστικό , ευαίσθητα δεδομένα, μη ευαίσθητα δεδομένα).
Το Οιονεί αναγνωριστικό (quasi-identifier, QID) είναι μια ανωνυμοποιημένη εκδοχή του αρχικού QID η οποία δημιουργείται εφαρμόζοντας κάποιες διαδικασίες ανωνυμοποίησης στα χαρακτηριστικά του QID που βρίσκεται στον αρχικό πίνακα. Οι λειτουργίες ανωνυμοποίησης αποκρύπτουν κάποιες λεπτομερείς πληροφορίες, ώστε αρκετές εγγραφές να «συσσωματώνονται» και να μην μπορούν να διακριθούν εύκολα.
Έτσι, εάν ένα άτομο συνδεθεί με μια εγγραφή μέσω του QID, το άτομο αυτό θα συνδέεται επίσης και με όλες τις άλλες εγγραφές που έχουν το ίδιο οιονεί αναγνωριστικό, καθιστώντας τη διασύνδεση δυσδιάκριτη.
Το πρόβλημα δηλαδή της ανωνυμοποίησης είναι να παραχθεί ένας ανώνυμος πίνακας Τ που να ικανοποιεί μια δεδομένη απαίτηση προστασίας δεδομένων προερχόμενη από κάποιο συγκεκριμένο μοντέλο απορρήτου αλλά που όμως θα διατηρεί και όσο το δυνατόν περισσότερη χρησιμότητα δεδομένων.
Ας δούμε πώς μπορεί να γίνει αυτό με παραδείγματα. Ας υποθέσουμε ότι έχουμε στη διάθεσή μας τους εξής πίνακες
(α) Πίνακας ασθενών.
|
Εργασία |
Φύλο |
Ηλικία |
Νόσος |
|
Μηχανικός |
Άντρας |
35 |
Ηπατίτιδα |
|
Μηχανικός |
Άντρας |
38 |
Ηπατίτιδα |
|
Δικηγόρος |
Άντρας |
38 |
HIV |
|
Συγγραφέας |
Γυναίκα |
30 |
Γρίπη |
|
Συγγραφέας |
Γυναίκα |
30 |
HIV |
|
Χορεύτρια |
Γυναίκα |
30 |
HIV |
|
Χορεύτρια |
Γυναίκα |
30 |
HIV |
β) Εξωτερικός πίνακας.
|
Ονομα |
Εργασία |
Φύλο |
Ηλικία |
|
Αλίκη |
Συγγραφέας |
Γυναίκα |
30 |
|
Βασίλης |
Μηχανικός |
Άντρας |
35 |
|
Καίτη |
Συγγραφέας |
Γυναίκα |
30 |
|
Τάκης |
Δικηγόρος |
Άντρας |
38 |
|
Αιμιλία |
Χορεύτρια |
Γυναίκα |
30 |
|
Γιώργος |
Μηχανικός |
Άντρας |
38 |
|
Δήμητρα |
Χορεύτρια |
Γυναίκα |
30 |
|
Σπύρος |
Δικηγόρος |
Άντρας |
39 |
|
Ειρήνη |
Χορεύτρια |
Γυναίκα |
32 |
Ανάλυση επίθεσης
Υποθέστε ότι ένα νοσοκομείο θέλει να διαθέσει τα αρχεία των ασθενών στον Πίνακα (α) σε ένα ερευνητικό κέντρο. Ας υποθέσουμε επίσης ότι το ερευνητικό κέντρο έχει πρόσβαση στον πίνακα (β) και γνωρίζει ότι κάθε άτομο με εγγραφή στον Πίνακα (β) έχει εγγραφή και στον Πίνακα (α). Ενώνοντας τους δύο πίνακες με βάση τα κοινά Εργασία, Φύλο, και ηλικία μπορούμε να ταυτοποιήσουμε το πρόσωπο με την Νόσο. Για παράδειγμα, ο Τάκης, ένας άνδρας δικηγόρος ο οποίος είναι 38 ετών, εντοπίζεται ως ασθενής με HIV από το οιονεί Αναγνωριστικό (QID):« Δικηγόρος, Άντρας, 38» μετά την ενοποίηση των πινάκων.
Ισχύει το ίδιο για την Αλίκη;
k-ΑΝΩΝΥΜΙΑ
Για να αποφευχθεί η σύνδεση των εγγραφών μέσω των QID, επινοήθηκε η έννοια της k-ανωνυμίας:
Αν μία εγγραφή στον πίνακα έχει κάποια τιμή qid, πρέπει να υπάρχουν τουλάχιστον k-1 άλλες εγγραφές με την ίδια τιμή qid. Με άλλα λόγια, το ελάχιστο πλήθος εγγραφών ανά QID θα πρέπει να είναι τουλάχιστον k. Ένας πίνακας που ικανοποιεί αυτήν την απαίτηση ονομάζεται k-ανώνυμος (k-anonymous). Σε έναν k-ανώνυμο πίνακα κάθε εγγραφεί δεν μπορεί να διακριθεί από τουλάχιστον k-1 άλλες εγγραφές σε σχέση με το QID. Κατά συνέπεια, η πιθανότητα σύνδεσης ενός θύματος με ένα συγκεκριμένο αρχείο μέσω του QID είναι το πολύ 1/k.
(γ) 3-ανώνυμος Πίνακας ασθενών.
| Εργασία | Φύλο | Ηλικία | Νόσος |
| Επαγγελματίας | Άντρας | [35-40) | Ηπατίτιδα |
| Επαγγελματίας | Άντρας | [35-40) | Ηπατίτιδα |
| Επαγγελματίας | Άντρας | [35-40) | HIV |
| Καλλιτέχνης | Γυναίκα | [30-35) | Γρίπη |
| Καλλιτέχνης | Γυναίκα | [30-35) | HIV |
| Καλλιτέχνης | Γυναίκα | [30-35) | HIV |
| Καλλιτέχνης | Γυναίκα | [30-35) | HIV |
(δ) 4-ανώνυμος εξωτερικός πίνακας.
| Όνομα | Εργασία | Φύλο | Ηλικία |
| Αλίκη | Καλλιτέχνης | Γυναίκα | [30-35) |
| Βασίλης | Επαγγελματίας | Άντρας | [35-40) |
| Καίτη | Καλλιτέχνης | Γυναίκα | [30-35) |
| Τάκης | Επαγγελματίας | Άντρας | [35-40) |
| Αιμιλία | Καλλιτέχνης | Γυναίκα | [30-35) |
| Γιώργος | Επαγγελματίας | Άντρας | [35-40) |
| Δήμητρα | Καλλιτέχνης | Γυναίκα | [30-35) |
| Σπύρος | Επαγγελματίας | Άντρας | [35-40) |
| Ειρήνη | Καλλιτέχνης | Γυναίκα | [30-35) |
Ο πίνακας (γ) δείχνει έναν 3-ανώνυμο πίνακα με γενίκευση του QID - Εργασία, Φύλο, Ηλικία από τον πίνακα (α) χρησιμοποιώντας την παρακάτω δενδρική δομή ταξινόμησης. Στην πραγματικότητα υπάρχουν δύο ομάδες ανά QID.
α) Επαγγελματίας, Άντρας, [35-40).
β) Καλλιτέχνης, Γυναίκα, [30-35].
Δεδομένου ότι κάθε ομάδα περιέχει τουλάχιστον 3 εγγραφές, ο πίνακας είναι 3-ανώνυμος. Αν συνδέσουμε τα αρχεία του Πίνακα (β) με τα αρχεία στον Πίνακα (γ) μέσω του QID, κάθε εγγραφή συνδέεται είτε με μηδέν είτε με τουλάχιστον 3 εγγραφές στον Πίνακα (γ).
ΠΟΛΛΑΠΛΑ ΟΙΟΝΕΙ ΑΝΑΓΝΩΡΙΣΤΙΚΑ (MULTIPLE QIDS)
Το μοντέλο k-ανωνυμίας υποθέτει ότι το QID είναι γνωστό στον εκδότη tvn δεδομένων. H πιο ασφαλής προσέγγιση είναι ιαυτή που απαιτεί ένα ενιαίο QID να περιέχει όλα τα χαρακτηριστικά που μπορούν να χρησιμοποιηθούν στο οιονεί αναγνωριστικό. Όσο περισσότερες ιδιότητες συμπεριλαμβάνονται στο QID, τόσο μεγαλύτερη προστασία k-ανωνυμίας θα παρέχει. Από την άλλη πλευρά όμως, αυτό σημαίνει ότι απαιτείται μεγαλύτερη παρέμβαση στα δεδομένα, προκειμένου να επιτευχθεί k-ανωνυμίας επειδή οι εγγραφές μιας ομάδας πρέπει να περιέχουν περισσότερες ιδιότητες. Για να αντιμετωπιστεί αυτό το ζήτημα, μπορούν να καθοριστούν πολλαπλά QID υποθέτοντας ότι ο εκδότης δεδομένων γνωρίζει τα QID εκείνα που μπορεί να είναι ευάλωτα για διασύνδεση.
Ένας εκδότης δεδομένων θέλει να δημοσιεύσει έναν πίνακα Τ (Α, Β, Γ, Δ, Ε), όπου το Ε είναι το ευαίσθητο δεδομένο και γνωρίζει ότι ο παραλήπτης του πίνακα έχει πρόσβαση σε προηγούμενα δημοσιευμένους πίνακες T1 (Α, Β, Χ) και Τ2 (Γ, Δ, Υ ), όπου Χ και Υ είναι χαρακτηριστικά που δεν υπάρχουν στον πίνακα Τ.
Για να αποφευχθεί η διασύνδεση των εγγραφών του Τ με πληροφορίες που σχετίζονται με το Χ ή το Υ, ο εκδότης των δεδομένων μπορεί να καθορίσει k-ανωνυμία στο QID1 = (Α, Β) και στο QID2= (Γ, Δ) για τον πίνακα Τ.
Αυτό σημαίνει ότι κάθε εγγραφή στο Τ δεν μπορεί να διακριθεί από μια ομάδα τουλάχιστον k εγγραφών σε σχέση με το QID1 και δεν μπορεί να διακριθεί από μια ομάδα τουλάχιστον k εγγραφών σε σχέση με το QID2. Οι δύο ομάδες δεν είναι απαραιτήτως οι ίδιες. Είναι σαφές ότι αυτή η απαίτηση υπονοείται από την k-ανωνυμία στο QID = A, B, Γ, Δ, αλλά η ύπαρξη k-ανωνυμίας και στο QID1 και στο QID2 δεν συνεπάγεται k-ανωνυμία στο QID.
Διαφοροποίηση ℓ (ℓ-diversity)
Η αρχή της διαφοροποίησης ℓ, που ονομάζεται ℓ-diversity επινοήθηκε για την πρόληψη των επιθέσεων μέσω διασύνδεσης εγγραφών. Η διαφοροποίηση ℓ. απαιτεί κάθε ομάδα qid ομάδα να περιέχει τουλάχιστον ℓ "καλά εκπροσωπούμενα" ευαίσθητα δεδομένα.
Η απλούστερη απόδοση του όρου "καλά εκπροσωπούμενα" είναι η διασφάληση ύπαρξης τουλάχιστον ℓ διακριτών τιμών για το ευαίσθητο δεδομένο ανά ομάδα qid.
Αυτό το διακριτό μοντέλο προστασίας ιδιωτικών δεδομένων με ℓ διαφοροποίηση, ικανοποιεί ικανοποιεί ταυτόχρονα και την k-ανωνυμία, όπου k = ℓ , επειδή κάθε ομάδα QID ομάδα τουλάχιστον ℓ εγγραφές.
Ορισμένα ευαίσθητες δεδομένα, είναι φυσικά πιο συχνά από άλλα σε μια ομάδα, επιτρέποντας σε έναν εισβολέα να συμπεράνει ότι μια εγγραφή στην ομάδα είναι πολύ πιθανό να παίρνει μια συγκεκριμένη τιμή. Για παράδειγμα, η γρίπη είναι πολύ πιο συχνή από τον ιό HIV. Για το λόγο αυτό προέκυψε η ανάγκη επινόησης μιας έννοιας ισχυρότερης από την έννοια της Διαφοροποίησης ℓ, αυτή της «Εντροπίας της Διαφοροποίησης ℓ»
Εντροπία της Διαφοροποίησης ℓ (ENTROPY ℓ-DIVERSITY).
Ένας πίνακας είναι εντροπικά διαφοροποιημένος κατά ℓ, εάν για κάθε ομάδα QID ισχύει: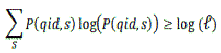 όπου S είναι ευαίσθητο δεδομένο και P (qid, s) είναι το κλάσμα των εγγραφών σε μια ομάδα qid που έχει την ευαίσθητη τιμή Σ. Αλγεβρικά ο παραπάνω τύπος αποδίδεται ως
όπου S είναι ευαίσθητο δεδομένο και P (qid, s) είναι το κλάσμα των εγγραφών σε μια ομάδα qid που έχει την ευαίσθητη τιμή Σ. Αλγεβρικά ο παραπάνω τύπος αποδίδεται ως 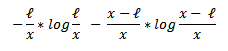
όπου ℓ = ℓ-diversity και x το πλήθος των κατηγοριών των ευαίσθητων δεδομένων.
ΜΗΝ ΑΝΗΣΥΧΕΙΤΕ ΜΕ ΤΑ ΠΟΛΛΑ ΜΑΘΗΜΑΤΙΚΑ – ΣΤΟ ΠΑΡΑΔΕΙΓΜΑ ΠΑΡΑΚΑΤΩ Η ΕΠΕΞΗΓΗΣΗ ΘΑ ΣΑΣ ΦΑΝΕΙ ΓΕΛΟΙΑ!
Η αριστερή πλευρά, που ονομάζεται εντροπία του ευαίσθητου χαρακτηριστικού, έχει την ιδιότητα ότι πιο ομοιόμορφα κατανεμημένες ευαίσθητες τιμές σε μια ομάδα qid παράγουν μια μεγαλύτερη τιμή. Επομένως, μια μεγάλη τιμή κατωφλίου συνεπάγεται λιγότερη βεβαιότητα απόδοσης συγκεκριμένου ευαίσθητου δεδομένου σε μια ομάδα.
Παράδειγμα Εντροπίας της Διαφοροποίησης ℓ
Εξετάστε τον Πίνακα (γ).
Για την πρώτη ομάδα Επαγγελματίας, Άντρας, [35 -40),
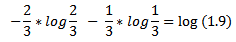
και για τη δεύτερη ομάδα Καλλιτέχνης, Γυναίκα, [30-35),
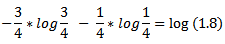
Έτσι, ο πίνακας ικανοποιεί Εντροπία διαφοροποίησης ℓ - αν το C <1,8.
ΛΕΙΤΟΥΡΓΙΕΣ ΑΝΩΝΥΜΟΠΟΙΗΣΗΣ – ΓΕΝΙΚΕΥΣΗ (GENERALIZATION)
Όπως είναι φυσικό, ο αρχικός πίνακας δεν πληροί καμία συγκεκριμένη απαίτηση απορρήτου και πρέπει να τροποποιηθεί. Η τροποποίηση αυτή γίνεται με την εφαρμογή μιας σειράς επεμβάσεων ανωνυμοποίησης η οποία διακρίνεται σε διάφορα είδη όπως είναι η γενίκευση, η καταστολή, η ανατόμηση, η μετάθεση και η αναδόμηση.
Εδώ θα μιλήσουμε μόνο για ένα είδος ανωνυμοποίησης, την γενίκευση (generalization). Για να την εφαρμόσουμε αντικαθιστούμε τις τιμές της συγκεκριμένης περιγραφής, (συνήθως τα χαρακτηριστικά ενός οιονεί αναγνωριστικού), με μια λιγότερο συγκεκριμένη περιγραφή. Για παράδειγμα τα τρία επαγγέλματα υδραυλικός, ηλεκτρολόγος, χτίστης, θα μπορούσαν να γενικευθούν στην έννοια «τεχνίτης».
Κάθε λειτουργία γενίκευσης αποκρύπτει κάποιες λεπτομέρειες στο QID. Για μια κατηγορική ιδιότητα, μια συγκεκριμένη τιμή μπορεί να αντικατασταθεί με μια γενική τιμή σύμφωνα με μια δεδομένη ταξινόμηση. Για ένα αριθμητικό χαρακτηριστικό, οι ακριβείς τιμές μπορούν να αντικατασταθούν με ένα διάστημα που καλύπτει τις ακριβείς τιμές. Αν υπάρχου ήδη διαστήματα τιμών, εφαρμόζεται τακτική παρόμοια με τα κατηγορικά χαρακτηριστικά. Ουσιαστικά στην γενίκευση αντικαθιστούμε μερικές τιμές με μια γονική τιμή της ταξινομίας στην οποία υπάγεται το χαρακτηριστικό.
ΣΥΣΤΗΜΑ ΓΕΝΙΚΕΥΣΗΣ ΠΛΗΡΟΥΣ ΤΑΞΙΝΟΜΙΑΣ
Στο παρακάτω σχήμα, όλες οι τιμές ενός χαρακτηριστικού γενικεύονται στο ίδιο επίπεδο του δένδρου ταξινόμησης.
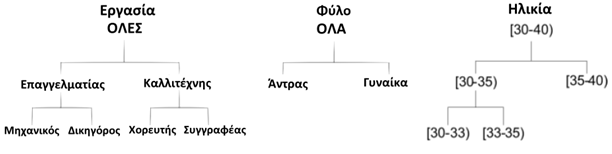
Για παράδειγμα, αν ο μηχανικός και ο δικηγόρος γενικευτούν στο Επαγγελματίας, τότε απαιτείται επίσης η γενίκευση του Χορευτή και του Συγγραφέα σε Καλλιτέχνη.
Ο χώρος αναζήτησης σε αυτό το σύστημα είναι πολύ μικρότερος από το χώρο αναζήτησης για άλλα συστήματα παρακάτω, αλλά η συμπύκνωση των δεδομένων είναι η μεγαλύτερη δυνατή λόγω της αναγκαιότητας ύπαρξης του ίδιου επιπέδου λεπτομέρειας σε όλες τις διαδρομές του δέντρου ταξινόμησης.
ΜΕΤΡΗΣΗ ΑΠΩΛΕΙΑΣ ΠΛΗΡΟΦΟΡΙΩΝ.
Η Απώλεια Πληροφορίας (i-Loss), είναι η μονάδα μέτρησης της ποσότητας της πληροφορίας που χάνεται όταν μια συγκεκριμένη τιμή μετατρέπεται σε μια πιο γενική. Αν, για ένα χαρακτηριστικό Α, μια συγκεκριμένη τιμή V γενικεύεται σε μια τιμή VG τότε η απώλεια πληροφορίας υπολογίζεται ως το κλάσμα των τιμών που γενικοποιούνται προς το σύνολο των τιμών του χαρακτηριστικού Α και αποδίδεται από τον εξής τύπο: 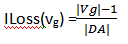 όπου, |Vg| είναι το πλήθος των τιμών που γενικοποιούνται σε Vg και |DA| είναι το πλήθος όλων των δυνατών τιμών του πεδίου Α.
όπου, |Vg| είναι το πλήθος των τιμών που γενικοποιούνται σε Vg και |DA| είναι το πλήθος όλων των δυνατών τιμών του πεδίου Α.
Για να υπολογιστεί η απώλεια πληροφορίας για ολόκληρη την εγγραφή, αθροίζονται οι τιμές των επιμέρους πεδίων με τη χρήση και μιας σταθεράς βαρύτητας W ανά χαρακτηριστικό.
![]()
Για να υπολογιστεί η απώλεια πληροφορίας σε ολόκληρο τον γενικευμένο πίνακα, αθροίζονται οι επιμέρους απώλειες της κάθε εγγραφής.
![]()
ΑΣΚΗΣΗ
Ο πίνακας Α πρόκειται να δημοσιοποιηθεί από ένα οργανισμό υγείας
| Πίνακας Α | |||
| Age | Sex | Zipcode | Disease |
| 5 | Μ | 12000 | gastric ulcer |
| 9 | Μ | 14000 | dyspepsia |
| 6 | Μ | 13000 | pneumonia |
| 8 | Μ | 19000 | bronchitis |
| 12 | Μ | 22000 | pneumonia |
| 15 | Μ | 25000 | pneumonia |
| 19 | Μ | 24000 | pneumonia |
| 21 | F | 58000 | flu |
| 26 | F | 36000 | gastritis |
| 28 | F | 37000 | flu |
| 56 | F | 33000 | flu |
Ο πίνακας Β είναι δημοσίως διαθέσιμος
| Πίνακας Β | |||
| Name | Age | Sex | Zipcode |
| Andy | 5 | Μ | 12000 |
| Bill | 9 | Μ | 14000 |
| Ken | 6 | Μ | 18000 |
| Nash | 8 | Μ | 10000 |
| Joe | 12 | Μ | 22000 |
| George | 15 | Μ | 25000 |
| Sam | 19 | Μ | 24000 |
| Linda | 21 | F | 58000 |
| Jame | 26 | F | 36000 |
| Sarah | 28 | F | 37000 |
| Mary | 56 | F | 33000 |
Αναγνωρίστε τα πεδία που αποτελούν το σύνολο QID, καθώς και αυτά που αποτελούν σύνολο Τ για τον πίνακα με τις εισαγωγές ασθενών στον οργανισμό υγείας.
Απάντηση
Τα πεδία που αποτελούν το σύνολο QID, είναι Q(AGE,SEX,ZIPCODE), δηλαδή οι κοινές εγγραφές. Τα πεδία που αποτελούν το σύνολο T, στον πίνακα με τις εισαγωγές ασθενών στο νοσοκομείο είναι T(AGE, SEX,ZIPCODE,DISEASE), δηλαδή όλες του οι εγγραφές
Υπολογίστε τα:
a. k για το k-anonymity
b. l για l-diversity
c. l για entropy l-diversity
Πριν προχωρήσουμε στην λύση της άσκησης, ας θυμηθούμε με απλά λόγια τη θεωρία που είδαμε ως τώρα.
Σημαντικός Κανόνας: Αν ο συνδυασμός του Q εμφανίζει έστω και μία ταυτοποιήσιμη εγγραφή, τότε ο πίνακας δεν είναι ανωνυμοποιημένος.
Στο παράδειγμα έχουμε λόγου χάρη Q(5, Μ, 12000) μόνο μία φορά, άρα αναγκαστικά ο ασθενής είναι ο Andy. Δηλαδή για τον συνδυασμό αυτόν το k=1. Σε αυτό το παράδειγμα ΟΛΕΣ οι εγγραφές είναι αναγνωρίσιμες γιατί τις ξεχωρίζει η ηλικία και ο ΤΚ, που όλα διαφορετικά μεταξύ τους. Αν είχαμε λόγου χάρη τρεις εγγραφές με Q(28,F,37000) δηλαδή 28άρες γυναίκες που να έμεναν στην ίδια πόλη, τότε δεν θα μπορούσαμε να βρούμε το όνομά τους και κατά συνέπεια αυτό το k θα ήταν 3. Όμως μετράει το μικρότερο k που βρίσκουμε στον πίνακα κι αν έστω κι ένα είναι =1, τότε ο πίνακας δεν είναι ανώνυμος.
Το ℓ-diveristy αναφέρεται στα ευαίσθητα δεδομένα, δηλαδή την αρρώστια. Όπως και στο k, αν μια αρρώστια μπορεί να αποδοθεί σε έναν μόνο ασθενή τότε το ℓ-diversity είναι 1. Αν δύο ή τρεις αρρώστιες μπορούν να αποδοθούν σε μια ομάδα που δεν ξεχωρίζουν τα άτομα τότε το ℓ-diversity είναι αντίστοιχα 2 ή 3. Το πώς υπολογίζεται μαθηματικά θα το δούμε στη συνέχεια που θα δημιουργήσουμε μικτές ομάδες με την γενίκευση των δεδομένων.
Για να βρούμε το entropy l-diversity, χρειάζεται το l-diversity να είναι μεγαλύτερο του 1, οπότε θα μιλήσουμε και γι’ αυτό παρακάτω. Προς το παρόν θα πούμε ότι το entropy l-diversity αφορά την συχνότητα με την οποία εμφανίζεται μια ασθένεια σε ένα γκρουπ ασθενών. Αν δηλαδή το 95% πάσχει από γρίπη και το 5% από 10 άλλες αρρώστιες, τότε σχεδόν σίγουρα μπορούμε να πούμε ότι κατά 95% οι ασθενείς του γκρουπ θα πάσχουν από γρίπη κι έτσι τους ταυτοποιούμε. Μπορεί δηλαδή να υπάρχουν 11 αρρώστιες σ’αυτή την ομάδα των ασθενών, όμως και πάλι είναι ταυτοποιήσιμη. Έτσι, όσο μεγαλύτερο είναι το entropy l-diversity τόσο καλύτερα.
Άρα απαντώντας στην άσκηση λέμε:
Στον ανωνυμοποιημένο πίνακα έχουμε
a. k =1, διότι υπάρχει έστω και ένα οιονεί αναγνωριστικό (QID) που εμφανίζεται μόνο μία φορά.
b. ℓ=1, διότι υπάρχει έστω και ένα οιονεί αναγνωριστικό που περιέχει μόνο μία ασθένεια
c. Το entropy ℓ-diversity δεν έχει νόημα να υπολογιστεί εδώ, διότι οι πίνακες έχουν k=1 και ℓ=1.
Για τα παρακάτω generalizations υπολογίστε :
a. k για το k-anonymity
b. l για ℓ-diversity
c. l για entropy ℓ-diversity
d. και iLoss
Generalization 1
Age : [1,10] [11-20] [21-60]
Zipcode : [10001-15000] [15001-20000] [20001-30000] [30001-60000]
Generalization 2
Age : [1-20] [20-60]
Zipcode : [10001-20000] [20001-30000] [30001-60000]
Απάντηση – Generalization 1
| Age | Sex | Zipcode | Disease | Age loss | Zipcode loss | Total i-loss |
| [1-10] | Μ | [10001-15000] | gastric ulcer | 0.27 | 0.09 | 0.36 |
| [1-10] | Μ | [10001-15000] | dyspepsia | 0.27 | 0.09 | 0.36 |
| [1-10] | Μ | [15001-20000] | pneumonia | 0.27 | 0.09 | 0.36 |
| [1-10] | Μ | [15001-20000] | bronchitis | 0.27 | 0.09 | 0.36 |
| [11-20] | Μ | [20001-30000] | pneumonia | 0.18 | 0.18 | 0.36 |
| [11-20] | Μ | [20001-30000] | pneumonia | 0.18 | 0.18 | 0.36 |
| [11-20] | Μ | [20001-30000] | pneumonia | 0.18 | 0.18 | 0.36 |
| [21-60] | F | [30001-60000] | flu | 0.27 | 0.27 | 0.55 |
| [21-60] | F | [30001-60000] | gastritis | 0.27 | 0.27 | 0.55 |
| [21-60] | F | [30001-60000] | flu | 0.27 | 0.27 | 0.55 |
| [21-60] | F | [30001-60000] | flu | 0.27 | 0.27 | 0.55 |
|
4.73 |
Ομαδοποιούμε τις ηλικίες και τους ταχυδρομικούς κωδικούς όπως λέει η άσκηση. Προκύπτουν 4 διακριτές ομάδες (ροζ, πράσινη, μοβ και κίτρινη) ουσιαστικά λόγω των κωδικών.
α. Εύρεση του iLoss
Το i-loss σημαίνει την απώλεια πληροφορίας που έχουμε λόγω ομαδοποίησης. Η απώλεια πληροφορίας υπολογίζεται ανά στήλη στις τιμές που ομαδοποιήσαμε, δηλαδή σε αυτή την περίπτωση το Αge και το zipcode.
To i-loss προκύπτει από τον τύπο
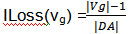
Το |Vg| είναι το πλήθος των τιμών που γενικοποιούνται σε Vg και |DA| είναι το πλήθος όλων των δυνατών τιμών του πεδίου Α. Δηλαδή το I-Loss υπολογίζεται αν μετρήσουμε το πλήθος των αρχικών τιμών που ενοποιούνται σε μια νέα τιμή και αφαιρέσουμε 1. Στη συνέχεια διαιρούμε με το σύνολο των αρχικών τιμών.
Δηλαδή για το Αge έχουμε “ενσωματώσει” 4 τιμές στο γκροθπ [1-10], 3 στο [11-20] και 4 στο [21-60]. Το σύνολο αρχικά είχε 11 μοναδικές τιμές. Άρα η απώλεια σε κάθε κελί του Age είναι για το 1ο γκρουπ = 0,27, για το 2ο γκρουπ = 0,18 και για το 3ο γκρουπ = 0,27
Αντίστοιχα για το Zipcode έχουμε “ενσωματώσει” 2 τιμές στο γκρουπ [10001-15000], 2 στο [15001-20000], 3 στο [20001-30000] και 4 στο [30001-60000]. Κι εδώ το σύνολο αρχικά είχε 11 μοναδικές τιμές. Άρα η απώλεια σε κάθε κελλί του Zipcode είναι για το 1ο και το 2o γκρουπ 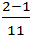 = 0,09 , για το 3ο γκρουπ = 0,18 και για το 3ο γκρουπ = 0,27
= 0,09 , για το 3ο γκρουπ = 0,18 και για το 3ο γκρουπ = 0,27
Το σύνολο της απώλειας σε κάθε γραμμή υπολογίζεται αθροιστικά, όπως επίσης και το σύνολο της απώλειας στον πίνακα ολόκληρο
| k-Anonymity | ||||
| QIDs | Sex | ZipCodes | k-values | min k-value |
| [1-10] | Μ | [10001-15000] | 2 | 2 |
| [1-10] | Μ | [15001-20000] | 2 | |
| [11-20] | Μ | [20001-30000] | 3 | |
| [21-60] | F | [30001-60000] | 4 | |
β. Εύρεση του k
Τώρα για να βρούμε το k, γράφουμε σε έναν καινούριο πίνακα μόνο μια φορά την κάθε έγχρωμη γραμμή, δηλαδή τα μοναδικά QID και δίπλα πόσες φορές εμφανίζονται στον αρχικό πίνακα. Αυτή η συχνότητα εμφάνισης είναι τα k-values. Το μικρότερο από αυτά είναι και το ζητούμενο k του πίνακα.
γ. Εύρεση του ℓ diversity
Για να βρούμε το ℓ-diversity ξαναφτιάχνουμε έναν παρόμοιο πίνακα που περιέχει τα μοναδικά QID αλλά αυτή τη φορά στη θέση του k-values, γράφουμε ℓ-values. Στη συνέχεια πάμε στον αρχικό πίνακα και μετράμε πόσα είδη ευαίσθητων δεδομένων (ασθενειών) παρατηρούνται σε κάθε ομάδα. Στην ροζ ομάδα λ.χ. έχουμε δύο είδη, gastric ulcer και dyspepsia, ενώ στην μωβ ομάδα έχουμε μόνο ένα είδος, pneumonia.
ΠΡΟΣΟΧΗ! Δεν καταμετρούμε απόλυτες τιμές εμφάνισης ασθενειών, αλλά το είδος τους! Δηλαδή όχι 3 πνευμονίες στο μωβ, μόνο 1 είδος.
| QIDs | Sex | ZipCodes | l-values | min L-value |
| [1-10] | Μ | [10001-15000] | 2 | 1 |
| [1-10] | Μ | [15001-20000] | 2 | |
| [11-20] | Μ | [20001-30000] | 1 | |
| [21-60] | F | [30001-60000] | 2 |
Επιλέγουμε κι εδώ την μικρότερη τιμή και την αποδίδουμε στο ℓ-divercity. Όπως είναι φανερό ένας πίνακας με ℓ-divercity=1, δεν είναι ανωνυμοποιημένος καθώς όλοι οι άρρωστοι που ανήκουν στην ομάδα αυτή θα πάσχουν από την ίδια ασθένεια και άρα είναι εύκολο να εντοπιστούν.
γ. Εύρεση του entropy ℓ diversity
Για να βρούμε το entropy ℓ-diversity επαναλαμβάνουμε τη διαδικασία με τον πίνακα μόνο που τώρα προσθέτουμε μια στήλη ακόμη πριν τη στήλη ℓ-values. Στην στήλη αυτή γράφουμε έναν αριθμό που προκύπτει από τον εξής τύπο:
![]()
όπου ℓ είναι οι τιμές από τον προηγούμενο πίνακα και
x είναι το πόσα είδη ασθενειών υπάρχουν στον αρχικό πίνακα. Στην περίπτωσή μας είναι 6: (gastric ulcer, dyspepsia, pneumonia, bronchitis, flu, gastritis).
| QIDs | Sex | ZipCodes | QIDs logs | l-values | min L-value |
| [1-10] | Μ | [10001-15000] | 0.276 | 1.9 | 1 |
| [1-10] | Μ | [15001-20000] | 0.276 | 1.9 | |
| [11-20] | Μ | [20001-30000] | 0.196 | 1.6 | |
| [21-60] | F | [30001-60000] | 0.276 | 1.9 |
Άρα για την πρώτη ροζ γραμμή ο τύπος γίνεται:
![]() = 0,276
= 0,276
Τον λογάριθμο του 10 για το κάθε κλάσμα το βρίσκουμε με κομπιουτεράκι πληκτρολογώντας πρώτα «2/6» και στη συνέχεια το πλήκτρο “log”.
Τέλος για να βρούμε την τιμή του L, στην αντίστοιχη στήλη, υψώνουμε το 10 στη δύναμη που προκύπτει στο προηγούμενο κελί, στο παράδειγμά μας δηλαδή, στην πρώτη γραμμή έχουμε 100,28=1,9.
Απάντηση – Generalization 2
| Age | Sex | Zipcode | Disease | Age loss | Zipcode loss | Total i-loss |
| [1-10] | Μ | [10001-20000] | gastric ulcer | 0.55 | 0.27 | 0.82 |
| [1-10] | Μ | [10001-20000] | dyspepsia | 0.55 | 0.27 | 0.82 |
| [1-10] | Μ | [10001-20000] | pneumonia | 0.55 | 0.27 | 0.82 |
| [1-10] | Μ | [10001-20000] | bronchitis | 0.55 | 0.27 | 0.82 |
| [11-20] | Μ | [20001-30000] | pneumonia | 0.55 | 0.18 | 0.73 |
| [11-20] | Μ | [20001-30000] | pneumonia | 0.55 | 0.18 | 0.73 |
| [11-20] | Μ | [20001-30000] | pneumonia | 0.55 | 0.18 | 0.73 |
| [21-60] | F | [30001-60000] | flu | 0.27 | 0.27 | 0.55 |
| [21-60] | F | [30001-60000] | gastritis | 0.27 | 0.27 | 0.55 |
| [21-60] | F | [30001-60000] | flu | 0.27 | 0.27 | 0.55 |
| [21-60] | F | [30001-60000] | flu | 0.27 | 0.27 | 0.55 |
|
7.67 |
k-Anonymity
| QIDs | Sex | ZipCodes | k-values | min k-value |
| [1-10] | Μ | [10001-15000] | 4 | |
| [11-20] | Μ | [20001-30000] | 3 | |
| [21-60] | F | [30001-60000] | 4 |
l-divercity
| QIDs | Sex | ZipCodes | l-values | min L-value |
| [1-10] | Μ | [10001-20000] | 4 | 1 |
| [11-20] | Μ | [20001-30000] | 1 | |
| [21-60] | F | [30001-60000] | 2 |
Βιβλιογραφική αναφορά σε αυτή τη σελίδα:
2020
ΣΥΝΟΠΤΙΚΟΣ ΧΑΡΤΗΣ ΤΟΥ ΣΑΪΤ
Αυτό το σάιτ χρησιμοποιεί Κώδικα Καταγραφής (ΚωΚ ή cookies) κυρίως για την προβολή διαφημίσεων από την Google - Μάθετε περισσότερα...
